データ分析が "攻め" の施策になる時代は終わった
ただのおもいつきです。
最近いろんな会社のデータ活用を支援していて感じるのですが、どこの会社も既になにかしらデータ分析に取り組んでいるというケースが増えてきました。
前までは少なくない会社が初めて取り組むとかそれに近い状態で、SWEに頼んで基幹システムからデータを抽出してもらって手元のエクセルとかで分析するみたいなレベル感でした。
これが、ここ数年は取り組んでいるが上手くいっていない部分を改善したいというところまで進んでいる会社がかなり増えてきているという感触があります。
たとえばデータ基盤を作ったけど多様なデータを上手く連携できていないとか、ダッシュボード作ったけど現場でアクションが上手く起こせないとか、そういうのはあるんですが少なくとも何かしらのデータ活用を1周2周してきた企業ばかりになってきました。
ビッグデータという言葉まで遡れば十数年以上前からデータ活用の波はデータサイエンスブームや機械学習ブームなどいくつかに分かれて来ており、最近は生成AIという技術によって更に加速しています。
なんだかんだでデータ活用という業界に10年弱ウロウロしている身ですが、昔はデータ活用といえば先進的な企業が攻めの施策として取り入れるという雰囲気がありました。DXという言葉もリスクを取って挑戦するという風潮でしたね。
それが、今となってはもはやデータ分析というのはまともな企業ならすでに着手していて当たり前という状態にまで変化してきました。少なくともそれに挑戦し1歩2歩は進んでいます。
これは企業の大きさとか関係なく起きており、現代でビジネスを上手くやろうとしたら多かれ少なかれデータを分析して活かすことがほぼ必須という世界になりつつあるということです。
もはやデータ分析というのは攻めの施策ではなく、やって当然でありやらなければ負けるといっても過言ではないでしょうね。
余談:攻めの反対は受けではありません
これからはデータ分析が受けで生成AI × データ分析の時代です
— Grahamian (@grahamian.bsky.social) 2025-05-23T06:00:47.730Z
Redshiftで連続した日付や月を生成する
PostgreSQLとかBigQueryならgenerate_seriesやgenerate_date_arrayのような関数を使うことで簡単につくることができますがRedshiftはgenerate_seriesが使えないのでちょっとテクニカルなことをしないといけません。
ここではrow_numberを使った実装を載せます。
もっといい方法があったら教えてください。
連続した日付を生成する
任意の日付を起点にして連続した日付を生成するときは次のように書きます。
select current_date + (row_number() over ()) as generated_date from table_name limit 10
この例文だと2024-09-17〜2024-09-26のリストが生成されます。
| generated_date |
|---|
| 2024-09-17 00:00:00 |
| 2024-09-18 00:00:00 |
| 2024-09-19 00:00:00 |
| 2024-09-20 00:00:00 |
| 2024-09-21 00:00:00 |
| 2024-09-22 00:00:00 |
| 2024-09-23 00:00:00 |
| 2024-09-24 00:00:00 |
| 2024-09-25 00:00:00 |
| 2024-09-26 00:00:00 |
current_date は単純に起点となる日付を記述しています。
過去1年分を動的に出力したいならdateadd関数とか使っていい感じにやりましょう。
任意の日付を起点にしていときは'2024-09-16'::date + (row_number() over ())みたいに書きます。
起点となる日付が生成されないので含めたいときは '2024-09-16'::date + (row_number() over ()) - 1 みたいに-1をつけるとよいでしょう。
table_nameはどこのテーブルでもいいですが生成したい日付のリストより長いテーブルが必要です。
row_numberがぐるぐる回って日付を追加していく仕組みなのでこの例だと10行以上あるテーブルを指定します。
limitは生成する日付の長さになります。
この例だと10日分生成されます。
連続した年月を生成する
上記の例は日付ごとに生成されていましたがこのままだと月や年ごとのリストを生成することができません。
月や年は次のようにかきます。
select dateadd( 'month', row_number() over(), current_date ) AS generated_date from tabale_name limit 12
この例文は2024-10-16〜2025-09-16のリストを生成します
| generated_date |
|---|
| 2024-10-16 00:00:00 |
| 2024-11-16 00:00:00 |
| 2024-12-16 00:00:00 |
| 2025-01-16 00:00:00 |
| 2025-02-16 00:00:00 |
| 2025-03-16 00:00:00 |
| 2025-04-16 00:00:00 |
| 2025-05-16 00:00:00 |
| 2025-06-16 00:00:00 |
| 2025-07-16 00:00:00 |
| 2025-08-16 00:00:00 |
| 2025-09-16 00:00:00 |
最初のdateaddの month は月次でリストを作成することを指定しています。
年次ならyearとしてください。
日次と同様に任意の日付を起点にしたいならdateaddとかを使ってcurrent_dateの部分を書き換えましょう。
起点のある日付が抜けてしまうので必要なら row_number() over() - 1 と書く部分も同じです。
たとえば今月から1年前のリストを作りたいならこんな感じに作るかな。
dateadd(
'month',
row_number() over() -1,
dateadd('year', -1, date_trunc('month', current_date))
)
テーブルとかlimitの部分は日次と同じ考え方なので省略。
説明は以上です。
BigQueryだと簡単にできることが思っていたより面倒だったので備忘録として残します。
ちなみにgenerate_series自体はredshiftでも動くといえば動くのですが同時にテーブルを参照しようとするとエラーになります。
なので連番のリストは作れるんだけどそれを使って分析できないという状態です。ややこしいね。
ITはどんどんおもしろくなっている
これはただのメモです。
ITという言葉の含意は広いのであれなんだけどITは楽しいとおもう。
自分はSWEというほど開発はしていないし詳しいわけじゃないけどITはとても楽しいとおもう。
というか日々楽しくなっている。
日進月歩という言葉がふさわしいくらい世界が進歩しているのを感じる。
それは、いわゆるAIに限らず他にも高速な計算機や回線、多種多様なサービスが広まったことにあるとおもう。
ほんの少し前まではITに触れるには高いコンピュータを買う必要があったりして敷居が高く難しいものだった。
少なくとも一家に1台PCがあればすごいくらいの温度感だったとおもう。
それが今では誰もがスマートフォンという非常に高性能で多機能な端末を持つようになった。
いろんなアプリケーションをインターネットを介して扱うことができる。
利用するだけじゃなくて開発したければ学ぶ方法はたくさんあるし即座に始めることができる。
本も動画もあるしブラウザで動作するようなものだってある。
いうまでも技術はすごい勢いで発展している。
AIばかり目立つけどもちろんそれ以外の技術はいろいろ進歩しているし、新しいサービスはどんどん生み出されている。
市場規模だってどんどん広がっている。
個人で作る人だって増えた。
プログラミングが初等教育に組み込まれるようになってこれからはもっと作り手が増えていくだろう。
現代では世界のあらゆるものにITは関係しITが関係ないものを探すのが難しいくらいの世界になってきた。
ITを使うことで新たな価値が創造されていくのを肌で感じるとてもエキサイティングな時代だとおもう。
一方でITをつまらないと感じる人もいるようだ。
それは個人の感性だから別になにか言うつもりはない。
ぼくはITがおもしろくなっていると感じるし、これからもっと楽しくなるだろうとおもってる。
なぜスプレッドシートでやっていた計算をデータ分析基盤に引っ越すことが難しいのか?
思いついたのでメモ
データ分析基盤を立ち上げるとほぼ間違いなく今までスプレッドシートで計算していた指標の計算をデータ分析基盤に引っ越すタスクが発生します。 これを実施すること自体は妥当でやるべきだとおもいます。 一方で、これは思っている10倍くらいは時間がかかるし場合によってはゼロから作り直したほうが早いくらいには大変な仕事になります。 なぜこのような問題が起きるのでしょうか? これは一般的な社内システムの開発と非常に似た問題を抱えています。
このタスクの目標は今までスプレッドシートなどでやっていた指標の計算を新しくできたデータ分析基盤上で計算することです。 シートの計算をSQLに置き換えるような作業だとおもってください。 指標はたとえば売上やアクティブユーザ数、広告の各種指標、プロダクトの指標といったものです。 あくまでも今まで計算されていたものであり今も定期的に更新して使っている指標です。
実際にスプレッドシートからデータ分析基盤へ引っ越しをしようとすると思わぬところでとにかく時間がかかります。 その問題は一言でいってしまえば仕様がわからないから迅速に実装できないという問題に尽きます。
詳細な仕様がわからない、といわれるとそんなバカなと思う人が多いのではないでしょうか。 実際にシートで計算されているならば計算を見ればいいですし、データを使っている人がいるならば仕様を把握しているはずです。 しかし、実際に実装に着手すると驚くほど仕様がわかりません。
なぜ仕様がわからないのでしょうか? これは全体を正確に把握している人がいないことが大きな原因の1つです。 指標を使っている人は大まかな仕様は理解していますが具体的に細かい部分を把握していないことがあります。 理由はさまざまですが「シートの計算を作ったのは昔だから忘れてしまった」「前任者から引き継いだので詳しくは知らない」あたりはよくあるケースです。
細かい部分について担当者が理解していないのであれば実装を見るしかないので当然時間がかかるようになります。 ただでさえ、実装者は計算の内容を理解していないので時間がかかってしまうのですがそれに加えて「そもそもシートが見やすいものになっていない」「計算が見やすいように書かれていない」「関係ない計算が紛れ込んでいる」…といった問題によってシートから処理の内容を読み取ることは簡単ではありません。 読み解くのは思っているよりもかなり時間がかかります。
ほかにも「データ抽出部分はエンジニアに任せたからわからない」というケースは頻発します。 この場合はそのデータ抽出を実装した人を探して仕様を確認する必要がでてきます。 似たようなケースとして「他のシートの数値をコピペしているからわからない」という場合もあります。 こうなると他のシートの仕様を理解する必要があり数珠繫ぎのように仕様が膨れ上がっていきます。
シートをまたいだ計算や前処理としてシートにはないスクリプトで計算しているような場合は処理があちこちに分散されるため処理の内容を把握することが困難になっていきます。 シートの計算をたどっていくと、いきなり計算ではなく数値がベタっと貼られた箇所が現れたりします。 つまり、どこかで計算した値をコピペしているのです。 こうなると、どこからきた数字なのか担当者に聞くしかありません。 1つのシートに集約されていない場合はどこからきたデータなのか担当者しか知ることができませんので、そこにぶつかるたびに担当者に問い合わせて確認する必要がでてきます。
単純な話ですが、関係者が増えれば増えるほど情報を整理する難易度と手間は増加します。 1つの指標の計算と言いながら何人にも確認しなければ仕様がわからないようであれば、そしてそれがいくつもあれば仕様の確認だけで莫大な時間を費やしてしまうことは想像できるでしょう。
また、担当者の理解を正しく実装者に伝えることも簡単ではありません。 仕様を100%伝えることは一般に難しい問題です。 だいたいで考慮や伝える内容に漏れが生まれます。 シートの計算と担当者の認識がズレることも起きます。 そうなると仕様通りに計算しているのに計算が合わずに原因追求し、考慮漏れであることを発見し修正する手間が発生します。
「すでに存在するシートの計算を移植するだけなのになぜこんなに時間がかかるのか?」と不思議に思うかもしれません。 実際はこのようにして小さなコミュニケーションコストが何重にも積み重なることで全体として引っ越しの工数が膨らんでしまいがちなのです。
AWS Redshift Serverless / Spectrum / Glue / DMS / S3 を使って素早くシンプルなデータ分析基盤を構築する
AWS上で完結するデータ分析基盤を構築する機会があったのでメモです。 案外こういう設計で作れるんだよって話がネットになかったので、細かい話はおいといて、全体としてこういう設計で素早く作れるって話を書きます。
データ分析基盤の設計としてはシンプルです。
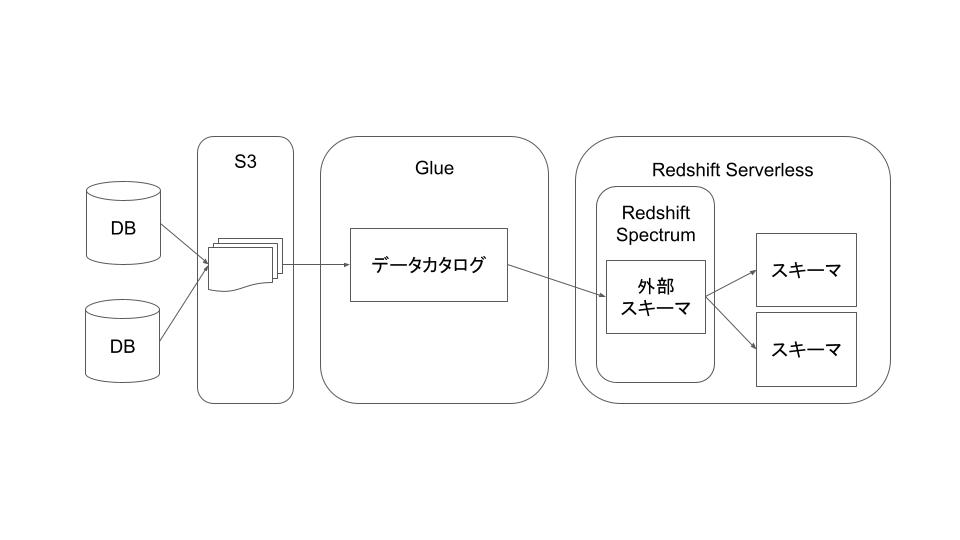
- データレイクとしてS3にデータを貯める
- Glueで読み込む
- データウェアハウスとしてRedshiftで分析する
という構造です。 順番に紹介します
データレイクへデータを蓄積する
まずはデータレイクの構築を目指します。
DMSを使うことができるならば簡単にデータを格納することができます。 parquetで出力することもできるので非常に都合がよい機能です。
AWS上にデータがなかったり他のサービスを連携する必要があるならばLambdaなんかを使って引っ張ってくる必要があるでしょう。 ここらへんは会社ごとによって都合があるので状況に応じて臨機応変に対応してください。
データを保存するパスを工夫することでpartitionを作ることが可能です。 次のように key=value という形でパスを切ることでそれがそのままpartitionになります。 これは複数設定できるので年月日で分けたり地域でわけたりとか工夫のしがいがあるポイントです
s3://bucket_name/table_name/dt=2024-01-01/000.parquet
保存したデータをSpectrumで扱えるようにGlueで読み込む
分析で使うRedshift Spectrumで扱うには外部スキーマというものを作成する必要があります。 この外部スキーマを作るためにGlueでデータカタログを作成します。 GlueにS3をクロールさせることで保存したデータを読み込んでデータカタログにテーブルを作成してくれます。
Glueにデータカタログを作成させるためにクローラを定義して動かします。 S3にあるデータを読み込むだけならばS3のパスを指定するだけでその配下をクロールしてくれます。 parquetならばとても簡単なのですがcsvだと上手くパースしてくれるように調整が必要かもしれません。 スケジュールの設定もできるので簡単に定期実行することができます。
Spectrumからデータカタログを外部スキーマとして読み込む
Glueが作ったデータカタログをSpectrumで外部スキーマとして読み込みます。 Redshift Serverlessは適当に立ち上げおきます。 データカタログを参照するように外部スキーマを作成することでデータカタログにあるテーブルを自動で参照できます。
あとは作った外部スキーマにあるテーブルを使ってクエリを作成することでデータ分析することができます。 お疲れ様でした。
この構造のメリットと注意点
メリット
安く素早く簡単に構築できるところが最大のメリットです。
Redshift Serverlessも含めてすべて従量課金制で使った分だけ課金されます。 どのサービスも非常に安価なので毎日1TBのデータを保存されるとかでなければ安価に済むでしょう。
ServerlessはRedshiftと違ってクラスタの管理もいらないのでとても簡単に立ち上げて使うことができます。 他のサービスもすべてマネージドサービスなので管理がいりません。
SpectrumはS3にあるデータをそのまま読み込むのでRedshiftに読み込む必要がありません。 とにかくS3に適切なパスでデータを突っ込んであればGlueが読み込んで分析できるようになるので簡単です。 1つ1つテーブル定義を作ったりする必要もないので楽です。 (parquetならともかくcsvだと修正が必要になりますけどね…)
SpectrumはRedshift本体との連携がスムーズです。 必要になればviewとかmaterialized viewとかもふつうに作ることができますしよく使うデータをRedshift本体に読み込んで高速化することもできます。 将来の拡張性が確保できる点は最初に構築する環境として良い点です。
注意点
デメリットというか注意点はいくつかあります。
Severlessは従量課金制なので課金金額がいくらになるか使ってみないとわからないのでそこは管理しにくいポイントです。 これはBigQueryも同じ問題を抱えていますが予算管理しにくいのは問題かもしれません。
Redshift上にデータを読み込んだときより処理は遅いです。 個人的には問題になるほどは遅くならないと感じていますが遅いのは間違いないです。 特に読み込むデータがcsvのままだと容量は食うので高いし処理は遅いしで最悪です。 (しかもパースできなくなったりして非常に苦労するので絶対にparquetにしましょう)
構築するときにデフォルトのままだと権限が足りないので権限を追加してあげる必要があります。 特にGlueがS3を読み込むところやSpectrumがGlueの情報を読み込むところで権限が足りないです。 エラーとかを見ればわかるとおもうので適宜追加してください。
データ活用に向けて詳細なロードマップを考えられる人材が足りない
なんか思いついたので1000文字で書く。
最近はフリーランスとしてデータ分析の文脈でデータ活用の支援をしているのですが、そのなかで「DXチームを立ち上げたけどうまくいかないので全体を進める手助けをしてほしい」という会社を何社か見かけました。
そういう会社、別に怠けているとか適当に仕事しているとか担当の人たちの能力が足りないとかではないんですよね。
(組織の硬直性とかもちろんそういう問題はあるとおもうんですけどそういうのは置いといて)みなさん優秀で熱心に取り込もうとしているんです。
でも、そもそも知識と経験が圧倒的に足りてないので「そもそもどういう方向に進めばいいのか誰もわからない」という状態になっていて暗中摸索になってしまっているんですよね。これを解決できる、つまり「データ活用するぞ!」ってなってからなにをしたらいいのか具体的に考えられる人がいないんですよ。
まあ、こういう話をすると「いやいや、これだけたくさんのプラクティスがあるし分析者だってたくさんいるじゃないですか」みたいに思うかもしれませんが「ゼロの状態から目指すべき方向とそこまでロードマップを具体的にイメージできる人」ってとても少ないんですよ。
なんとなーく分析基盤を作る必要があるとか、KPIはこういう感じで〜ってイメージを持てる人はわりといると思うんですよね。そこからもう1歩2歩進んで「このKPIを作って事業部とはこういう関わり方で進めよう」とか「ダッシュボードを作るためにこういうデータがと基盤が必要で開発者はどれくらい必要でスケジュールはこう」ってことが分かる人がいないんです。
こういうことができる人がいないとどうなるかというと大きく物事を動かすことができないのでとにかく手元でやれることをやって終わりになってしまうんですね。
事業部を巻き込んでやるにしても「で?その数値をみるとどうなるの?」とか「やるのはいいけど、どれくらい人が必要なの?予算は?」って聞かれたときに説明ができなかったりするとやっぱり事業部として受け入れがたいというのは当然の反応だと思うんですよね。
じゃあこういう状況どうしたらいいのかというと、シンプルにシニアで全体のロードマップを描けて推進できるようなシニアな人材をトップに据えてやるしかないなということになるでしょう。
どうしてもDXチームみたいなので社内からのスライドで人員を揃えたりするので知識と経験が不足しがちなんですが、採用してもいいし業務委託でもいいですけど、チームのトップは既存の人材のスライドではなく経験豊富な人材を入れるとスムーズなんじゃないかなとおもいます。